Sejarah
Tahun 1914, Emanuel Goldberg telah mulai membuat sistem OCR yang berfungsi untuk telegram dan alat baca untuk orang tunanetra. Sistem OCR terus dikembangkan hingga kini sehingga dapat menghasilkan akurasi yang lebih baik bahkan dalam situasi-situasi yang dimana karakter sulit untuk dikenali.
Latar Belakang
Salah satu tantangan yang hadapi adalah mengubah aplikasi fisik menjadi berbentuk aplikasi elektronik. Isian yang harus diisi oleh konsumen merupakan data pribadi yang tidak sulit untuk dicari, namun data yang dibutuhkan cukup banyak. Rata-rata sebuah aplikasi dapat memiliki 7 halaman yang menanyakan berbagai macam pertanyaan. Belum ditambah dengan dokumen-dokumen pendukung yang harus dilengkapi oleh konsumen. Dengan adanya teknologi yang semakin pesat kemajuannya tentu ingin memberikan sebuah fitur yang dapat mempermudah dalam mengisi aplikasi. Teknologi OCR dapat membantu nasabah untuk melakukan ekstraksi data secara otomatis dari dokumen yang telah diunggah. Kemudian data tersebut dapat diisikan secara otomatis ke isian yang sesuai. Fitur ini sangat menguntungkan bagi kedua belah pihak. Bagi nasabah jumlah isian data yang harus diisikan secara manual dapat dikurangi secara drastis, bagi perusahaan sendiri dapat meningkatkan kredibilitas data yang ada karena isian data diambil langsung dari dokumen asli.

Pengertian
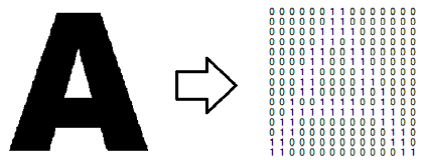
Optical character recognition (OCR) adalah proses konversi gambar huruf menjadi karakter ASCII yang dikenali oleh komputer. Gambar huruf yang dimaksud dapat berupa hasil scan dokumen, hasil print-screen halaman web, hasil foto, dan lain-lain.
Sebuah perangkat lunak yang mengubah teks dalam format berkas citra atau gambar ke dalam format teks yang bisa dibaca dan disunting oleh aplikasi komputer. Berkas teks berformat citra tersebut didapatkan dengan cara memindai atau memfoto sebuah buku, manuskrip, tulisan di papan pengumuman, ataupun materi kuliah di papan tulis dsb
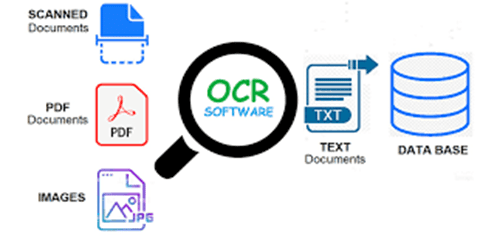
Tahun 1914, Emanuel Goldberg telah mulai membuat sistem OCR yang berfungsi untuk telegram dan alat baca untuk orang tunanetra. Sistem OCR terus dikembangkan hingga kini sehingga dapat menghasilkan akurasi yang lebih baik bahkan dalam situasi-situasi yang dimana karakter sulit untuk dikenali. Alat yang digunakan untuk memindai adalah pemindai (scanner) atau kamera baik kamera DSLR ataupun kamera di ponsel pintar.
Contoh OCR : image to teks

Salah satu kebutuhan mengapa perlu konversi gambar huruf menjadi karakter ASCII adalah karakter ASCII memiliki kapasitas penyimpanan yang lebih kecil. Contohnya, suatu paragraf di-printscreen dan disimpan dalam format png. Paragraf tersebut juga di-copy dan disimpan dalam format .txt. Untuk file gambar, memiliki size 42KB, sedangkan untuk file teks, memiliki size 1KB. Dari sini bisa terlihat bahwa file gambar akan selalu relatif lebih besar ketimbang menyimpan langsung teks ASCII-nya saja.
Deteksi OCR
- Angka
- Huruf
- Tanda Baca (glyph)


Fungsi OCR
- Data entry secara otomatis
- Menyalin/mengedit buku hasil scan
- Mengkonversi tulisan tangan ke dokumen digital
- Membuat dokumen tulis tangan agar bisa di-index
- Dan lain-lain
Aplikasi OCR
Pengaplikasian OCR sendiri memungkinkan komputer untuk melakukan proses lebih lanjut. Pengenalan karakter seperti ini digunakan untuk :
- Sistem baca otomasi untuk tunanetra
- Translasi bahasa asing
- Identifikasi Plat nomor
- Pengetesan CAPTCHA
- Masalah teks lainnya.
Layout OCR
Hasil dari OCR bisa disimpan langsung dalam bentuk ASCII, namun untuk kasus tertentu, butuh disimpan layout-nya. Yang dimaksud dengan layout adalah posisi paragraf, margin, dan lainnya, sehingga sama persis dengan gambar yang diolah. Layout butuh disimpan contohnya dalam kasus konversi hasil scan buku ke dalam file .doc, tentunya posisi paragraf dan lainnya perlu disamakan. Untuk menyimpan layout, dapat disimpan menggunakan suatu format XML (Extended Markup Language) bernama ALTO (Analyzed Layout and Text Object) yang dokumentasinya dapat ditemukan di http://www.loc.gov/standards/alto/
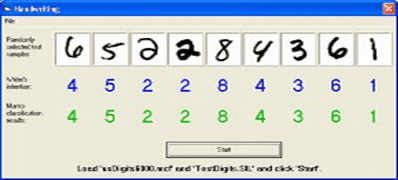
Klasifikasi Character Recognition
1.Optical Character Recognition (OCR)
2.Handwritten Character Recognition (HCR).
Akurasi pada HCR biasanya masih lebih rendah dikarenakan besarnya perbedaan bentuk dan tipe tulisan. Perbedaan karakter dalam Bahasa juga berpengaruh besar, contohnya: tulisan kanji mandarin, jepang, dan lainnya
Proses OCR
- Pra-pemrosesan (Preprocessing)
- Tahap ekstraksi fitur
- Proses pengenalan
- Paska-proses
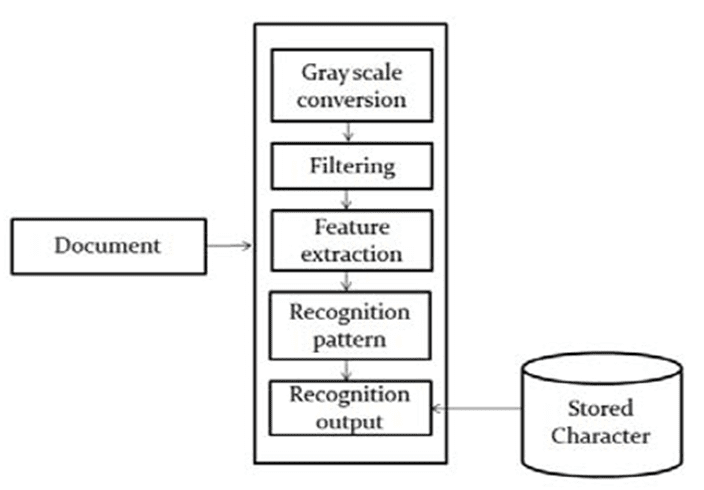
Sistem Preprocessing (1)
Bertujuan untuk mendapatkan karakter tunggal dari sebuah teks terpindai dalam kondisi yang bagus dan bersih sehingga memudahkan proses pengenalannya.
Teknik yang digunakan : Gray Scalling/Thresholding, Smoothing, Scaling, Stroke Thinning.

Metode Perspektif Citra Teks
Derau yang ditimbulkan oleh proses pemindaian atau pemotretan bisa berupa citra teks yang miring, teks yang melengkung di tengah karena ketebalan buku, serta kerangka teks yang berbentuk trapezium.
Koreksi bentuk geometri dan perspektif teks dilakukan dengan metode yang sama dengan deteksinya, hanya dalam koreksi ini dicari besar sudut kemiringan atau kurva lengkung, kemudian teks akan dirotasi sesuai dengan besaran sudut yang didapatkan.
- Komponen terhubung (Connected Components)
- Analisis Profil Proyeksi (Projection profile analysis)
- Analisis Komponen Utama (Principle Componenet Analysis a.k.a. PCA)
- Hough Transform (Verma & Malik, )
- Korelasi silang (Cross correlation) (Verma & Malik)
Saat citra teks sudah bersih dan memilliki orientasi geometrik yang tegak lurus, maka dilakukan pemisahan antara piksel karakter (biasanya berwarna hitam) dari piksel latar belakangnya (biasanya berwarna terang). Proses ini disebut segmentasi teks. Setelah itu, dilakukan juga segmentasi baris yakni proses memotong rangkaian karakter per baris. Proses segmentasi baris ini dikenal juga sebagai segmentasi horisontal. Untuk mendapatkan tiap karakter, maka dari tiap baris segmen dilakukan pemotongan secara vertikal berdasarkan spasi kosong atau piksel dengan warna yang terang yang memisahkan satu karakter dengan karakter di sebelah kanan atau kirinya.
Feature Extraction (2)
Feature Extraction adalah proses untuk mendapatkan informasi terhadap object ataupun kelompok object untuk memfasilitasi proses klasifikasi. Tujuan dari ekstraksi fitur adalah untuk menemukan atribut pola-pola karakter yang terpenting dan berbeda dari karakter lainnya agar bisa diklasifikasikan, contoh yang diekstrak :
- Fitur garis: garis lurus, lengkung dan jumlah garis
- Fitur topologi: titik-titik ujung akhir, titik persilangan
- Sudut
- Fitur biner yang diekstraksi dari citra keabuan.
Metode Ekstraksi Fitur
Tahap ekstraksi fitur ini bisa disamakan dengan pengubahan bentuk fisik karakter (terlepas apakah karakter tersebut sebuah abjad, aksara, atau alfabet) ke dalam model matematis yang bisa membedakan antara satu karakter, contohnya ‘l’, dari karakter lainnya, contohnya, ‘i’. Hasil pemetaan sebuah bentuk fisik karakter menjadi angka-angka dalam sebuah matriks atau vektor inilah yang akhirnya disebut sebagai fitur karakter.
- Hough Transform
- Aspect ratio
- moment invariants
- zoning
- Fourier transforms
Proses Pengenalan (3)
Pattern Recognition dilakukan berdasarkan format data binary yang ada, kemudian membagi binary kedalam 5 track, dimana setiap track dibagi lagi menjadi 8 sector. Keterkaitan matrix track dan sector berguna untuk mendeteksi sekelompok pixel di setiap bagian. Tujuan akhir dari pengenalan ini tentunya adalah untuk memberikan label kelas pola-pola karakter yang telah direpresentasikan.
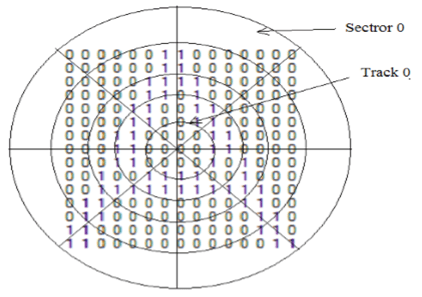
Metode Pengenalan Karakter
- Pendekatan statistic :
- Inferensi Bayes: termasuk Naïve Bayes
- Maximum likelihood
- Regresi linear
- Pendekatan Jaringan Syaraf Tiruan :
- Back-propagation Neural Network
- Convolutional Neural Network (CNN)
- Pendekatan berbasis kernel :
- Kernel Linear bagus untuk klasifikasi biner/linear
- Kernel RBF (Radial Basis Function) untuk klasifikasi data non-linear
- Kernel Gaussian
- Model grafis :
- Model regresi polinomial
- Model Gaussian linear
Postprocessing (4)
Setiap sistem OCR yang dibangun dengan algoritma tercanggih pun selalu membuat kesalahan, dalam arti tidak semua karakter yang dibaca dikonversikan ke karakter padanannya. Pada umumnya proses yang dilakukan pada tahap ini adalah proses koreksi ejaan sesuai dengan bahasa yang digunakan. Dikenal juga sebagai proses koreksi karena modul ini bertugas untuk mengoreksi kesalahan yang sering dilakukan di tataran kata.
Software OCR
- ABBYY FineReader OCR
- Cakra
- GOCR
- Falcon32
- IPStudio
- Microsoft Office Document Imaging
- NovoDynamics VERUS
- Ocropus
- OmniPage
- Readiris
- ReadSoft
- SmartScore
- Tesseract (software)
- TopSoft TopOCR
- Ocrad
Optical Mark Reader (OMR)
Optical Mark Reader (OMR) adalah perangkat “membaca” tanda pensil bulatan yang discan dalam bentuk kompatibel NCS bentuk seperti survey atau jawaban test. Bisa juga dijelaskan dalam bentuk pilihan ganda computer.
Dalam dokumen ini The Optical Mark Reader akan disebut sebagai pemindai atau OMR. Bentuk tes computer yang dirancang untuk OMR NCS dikenal sebagai bentuk scan yang kompatibel. Tes dan survey selesai pada bentuk ini dibaca oleh pemindai, diperiksa dan hasilnya disimpan ke sebuah file.
Data ini dapat di konversi menjadi ouput file dari beberapa format yang berbeda, tergantung pada jenis output yang anda inginkan.
Fungsi
OMR biasanya digunakan untuk survey dan ujian (test). Berbeda dengan OCR tingkat kebenaran OMR mencapai 100%.
Beberapa perangkat OMR mengunakan bentuk-bentuk yang dicetak ke “transoptic” kertas dan mengukur jumlah cahaya yang melewati kertas, dengan demikian suatu tanda di kedua sisi kertas akan mengurangi jumlah sinar yang melewati kertas.
Berbeda dengan perangkat OMR khusus, perangkat lunak Desktop OMR memperbolehkan user untuk membuat bentuk-bentuk mereka sendiri dalam pengolahan kata dan mencetaknya pada printer laser. OMR lunak yang kemudian bekerja dengan common pemindai gambar desktop dengan document feeder untuk memproses formulir yang diisi sekali.