Definisi Data Mining
Banyak sekali definisi mengenai apa itu data mining. Data mining merupakan suatu alat yang memungkinkan para pengguna untuk mengakses secara cepat data dengan jumlah yang besar.
Pengertian yang lebih khusus dari data mining, yaitu suatu alat dan aplikasi menggunakan analisis statistik pada data.
Data mining adalah suatu proses ekstraksi atau penggalian data dan informasi yang besar, yang belum diketahui sebelumnya, namun dapat dipahami dan berguna dari database yang besar serta digunakan untuk membuat suatu keputusanbisnis yang sangat penting.
Data mining adalah sebuah proses percarian secara otomatis informasi yang berguna dalam tempat penyimpanan data berukuran besar.
Istilah lain yang sering digunakan diantaranya knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, dan business intelligence.

Teknik data mining digunakan untuk memeriksa basis data berukuran besar sebagai cara untuk menemukan pola yang baru dan berguna. Tidak semua pekerjaan pencarian informasi dinyatakan sebagai data mining.
Sebagai contoh, pencarian record individual menggunakan database management system atau pencarian halaman web tertentu melalui query ke semua search engine adalah pekerjaan pencarian informasi yang erat kaitannya dengan information retrieval.
Teknik-teknik data mining dapat digunakan untuk meningkatkan kemampuan sistem-sistem information retrieval.
Baca juga : Algoritma
Data mining adalah bagian integral dari knowledge discovery in databases (KDD).Keseluruhan proses KDD untuk konversi raw data ke dalam informasi yang berguna ditunjukkan dibawah ini :
Data input dapat disimpan dalam berbagai format seperti flat file, spreadsheet, atau tabel-tabel relasional, dan dapat menempati tempat penyimpanan data terpusat atau terdistribusi pada banyak tempat.
Menurut para ahli (Efraim Turban, dkk 2005) Tujuan dari penambangan data ini untuk mengekstraksi serta mengidentifikasi suatu data demi informasi tertentu yang berhubungan dengan suatu database besar atau big data.
Terdapat beberapa istilah pula yang memiliki makna hampir sama dengan penambangan data meskipun definisi khususnya berbeda seperti Knowledge discovery in databases (KDD), analisa data atau pola, ekstraksi pengetahuan, kecerdasan bisnis, data arkeologi, dan data dredging.
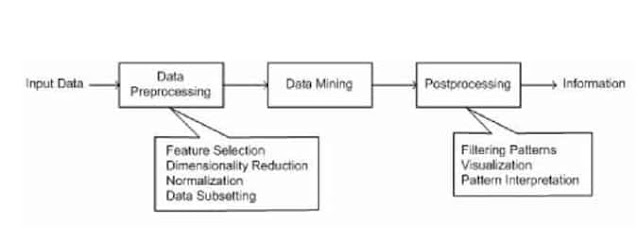
Tujuan dari preprocessing adalah mentransformasikan data input mentah ke dalam format yang sesuai untuk analisis selanjutnya.
Langkah-langkah yang terlibat dalam preprocessing data meliputi mengabungkan data dari berbagai sumber, membersihkan (cleaning) data untuk membuang noise dan observasi duplikat, dan menyeleksi record dan fitur yang relevan untuk pekerjaan data mining.
Karena terdapat banyak cara mengumpulkan dan menyimpan data, tahapan preprocessing data merupakan langkah yang banyak menghabiskan waktu dalam KDD.
Hasil dari data mining sering kali diintegrasikan dengan decision support system (DSS). Sebagai contoh, dalam aplikasi bisnis informasi yang dihasilkan oleh data mining dapat diintegrasikan dengan tool manajemen kampanye produk sehingga promosi pemasaran yang efektif yang dilaksanakan dan dapat diuji.
Integrasi demikian memerlukan langkah post processing yang menjamin bahwa hanya hasil yang valid dan berguna yang akan digabungkan dengan DSS.
Salah satu pekerjaan dan postprocessing adalah visualisasi yang memungkinkan analyst untuk mengeksplore data dan hasil data mining dari berbagai sudut pandang. Ukuran-ukuran statistik dan metode pengujian hipotesis dapat digunakan selama post processing untuk membuang hasil data mining yang palsu.
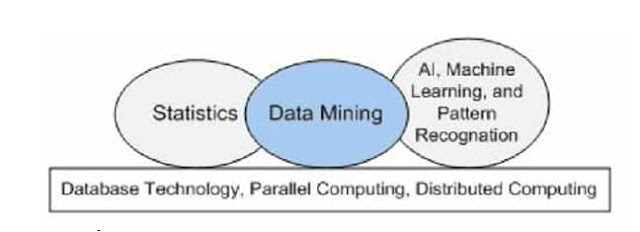
Secara khusus, data mining menggunakan ide-ide seperti pengambilan contoh, estimasi, dan pengujian hipotesis, dari statistika dan algoritme pencarian, teknik pemodelan, dan teori pembelajaran dari kecerdasan buatan, pengenalan pola, dan machine learning.
Data mining juga telah mengadopsi ide-ide dari area lain meliputi optimisasi, evolutionary computing, teori informasi, pemrosesan sinyal, visualisasi dan information retrieval.
Sejumlah area lain juga memberikan peran pendukung dalam data mining, seperti sistem basis data yang dibutuhkan untuk menyediakan tempat penyimpanan yang efisien, indexing dan pemrosesan query. ditunjukkan hubungan data mining dengan area- area lain dibawah ini.
Istilah dalam Data Mining
- Knowledge Presentation (di mana gambaran teknik visualisasi dan pengetahuan digunakan untuk memberikan pengetahuan yang telah ditambang kepada user).
- Data Selection (di mana data yang relevan dengan tugas analisis dikembalikan ke dalam database)
- Data Transformation (di mana data berubah atau bersatu menjadi bentuk yang tepat untuk menambang dengan ringkasan performa atau operasi agresi)
- Data Cleaning (untuk menghilangkan noise data yang tidak konsisten)
- Data Integration (di mana sumber data yang terpecah dapat disatukan)
- Data Mining (proses esensial di mana metode yang intelejen digunakan untuk mengekstrak pola data)
- Pattern Evolution (untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan atas beberapa tindakan yang menarik)
Fungsi Data Mining
Penambangan data adalah suatu proses yang memiliki banyak fungsi. Fungsi utamanya yaitu untuk mendapatkan informasi penting yang nantinya bisa bermanfaat. Jika dijabarkan lebih lanjut, berikut fungsi dasarnya.
- Prediction
Prediction atau fungsi prediksi merupakan salah satu fungsi data mining. Maksudnya yaitu dari proses nanti akan menemukan pola tertentu dari suatu data. Pola tersebut dapat diketahui dari variabel-variabel yang ada pada data. Pola yang didapat bisa digunakan untuk memprediksi variabel lain yang belum diketahui nilai ataupun jenisnya.
Karena itulah fungsi satu ini dikatakan sebagai fungsi prediksi. Nantinya bisa digunakan untuk memprediksi variabel tertentu yang tidak ada dalam suatu data. Hal ini tentunya memudahkan dan menguntungkan bagi mereka pemilik kepentingan yang memerlukan prediksi akurat untuk membuat hal penting tersebut menjadi lebih baik.
- Description
Fungsi selanjutnya adalah description atau fungsi deskripsi. Maksud dari fungsi deskripsi ini yaitu untuk memahami lebih jauh tentang data yang diamati. Jadi dengan melakukan proses, diharap mampu mengetahui perilaku dari data tersebut yang nantinya bisa digunakan untuk mengetahui karakteristik dari data yang dimaksud.
Data mining nantinya bisa menemukan pola tertentu yang tersembunyi dalam sebuah data. Dengan pola yang berulang dan bernilai itulah karakteristik data bisa diketahui. Hal satu ini tentunya memberikan banyak manfaat dan dapat meningkatkan pengetahuan.
- Klasifikasi
Fungsi lainnya adalah fungsi klasifikasi atau classification. Maksud dari fungsi klasifikasi yaitu data yang ada akan diproses sehingga akan ditemukan fungsi atau model tertentu yang menggambar konsep dari suatu data. Model atau fungsi tersebut nantinya akan memisahkan tiap data menjadi kelompok-kelompok tertentu.
Kelompok data tersebut nantinya bisa digunakan untuk meramalkan kecenderungan suatu data di masa depan. Pengelompokan atau pengklasifikasian data juga dapat memudahkan pemilik data saat mencari data yang dibutuhkan.
- Asosiasi
Maksud dari fungsi asosiasi atau analisis asosiasi yaitu penggunaannya untuk menemukan kombinasi atau aturan assosiatif dari suatu data. Jadi data yang ada nantinya diproses sehingga akan menemukan informasi tentang hubungan variabel satu dengan lainnya.
Agar mudah dipahami, contoh permisalannya pada analisis pembelian barang di swalayan. Semisal dari data pembelian diproses dan ternyata memperoleh hasil hubungan antara pembelian mie dan kecap. Jika besar kemungkinan pelanggan membeli mie dan kecap secara bersamaan, maka pihak swalayan bisa memanfaatkan informasi tersebut untuk mengatur penempatan mie dan kecap.
Kecap bisa diletakkan di rak yang tidak jauh dari mie. Bisa juga menggunakan kecap sebagai bonus pembelian mie atau bisa juga menggunakan cara lain, yang jelas menggambarkan bentuk hubungan mie dan kecap. Hal ini tentu saja menguntungkan.
Baca juga : Teknik Machine Learning
Tujuan Data Mining
- Explanatory adalah Untuk menjelaskan beberapa kondisi penelitian, seperti mengapa penjualan truk pick up meningkat di colorado.
- Confirmatory Untuk mempertegas hipotesis, seperti halnya 2 kali pendapatan keluarga lebih suka di pakai untuk membeli peralatan keluarga, di bandingkan dengan satu kali pendapatan keluarga.
- Exploratory Menganalisis data untuk hubungan yang baru yang tidak di harapkan, seperti halnya pola apa yang cocok untuk kasus penggelapan kartu kredit.
Metode Data Mining
sebagai salah satu bagian dari sistem informasi, data mining menyediakan perencanaan dari ide hingga implementasi akhir. Komponen-komponen dari rencana data mining adalah sebagai berikut.
- Analisa Masalah (Analyzing the Problem) Data asal atau data sumber harus bisa ditaksir untuk dilihat apakah data tersebut memenuhi kriteria data mining. Kualitas kelimpahan data adalah faktor utama untuk memutuskan apakah data tersebut cocok dan tersedia sebagau tambahan. Hasil yang diharapkan dari dampak data mining harus dengan hati-hati dimengerti dan dipastikan bahwa data yang diperlukan membawa informasi yang bisa diekstrak.
- Mengekstrak dan Membersihkan Data (Extracting dan Cleansing The Data) Data pertama kali diekstrak dari data aslinya, seperti dari OLTP basis data, text file, Microsoft Acces Database, dan bahkan dari spreadsheet, lalu data tersebut diletakan dalam data warehouse yang mempunyai sruktur yang sesuai dengan data model secara khas. Data Transformation Service (DTS) dipakai untuk mengekstrak dan membersihkan data dari tidak konsistennya dan tidak kompatibelnya dengan format yang sesuai.
- Validitas Data (Validating the Data) Sekali data telah diekstrak dan dibersihkan, ini adalh latihan yang bagus untuk menelusuri model yang telah kita ciptakan untuk memastikan bahwa semua data yang ada adalah data sekarang dan tetap.
- Membuat dan Melatih Model (Creating and Training the Model) Ketika algoritma diterapkan pada model, struktur telah dibangun. Hal ini sangatlah penting pada saat ini untuk melihat data yang telah dibangun untuk memastikan bahwa data tersebut menyerupai fakta di dalam data sumber.
- Query Data dari Model Data Mining (Querying the Model Data) Ketika model yang telah cocok diciptakan dan dibangun, data yang telah dibuat tersedia untuk mendukung keputusan. Hal ini biasanya melibatkan penulisan front end query aplikasi dengan program aplikasi/suatu program basis data.
- Evaluasi Validitas dari Mining Model (Maintaining the Validity of the Data Mining Model) Setelah model data mining terkumpul, lewat bebrapa waktu, karakteristik data awal seperti granularitas dan validitas mungkin berubah. Karena model data mining dapat terus berubah seiring perkembangan waktu.
Tahapan Data Mining
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lainnya. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining.
Proses KDD ada 5 tahapan yang dilakukan secara terurut, yaitu:
- Seleksi
Tahapan pertama dalam adalah seleksi. Proses seleksi merupakan proses penyeleksian data. Data yang diseleksi akan ditransformasikan ke format yang sesuai untuk analisis data. Seleksi data menggunakan beberapa kriteria. Data hasil seleksi kemudian akan disimpan di suatu berkas terpisah yang kemudian akan diolah atau dilakukan proses data mining.
- Preprocessing
Sebenarnya tahapan ini hampir sama dengan proses pemecahan pola. Hanya saja tahapan ini ditulis secara umum, tidak menjurus ke pemecahan pola. Nah dalam tahap processing, data yang tidak valid dan tidak dibutuhkan akan dibuang. Jadi akan terjadi pembersihan data yang informasinya tidak terlalu dibutuhkan. Data yang duplikat, yang tidak konsisten, dan data yang salah akan diperiksa dan dibersihkan.
- Transformasi
Tahapan selanjutnya adalah transformasi. Proses transformasi atau coding merupakan proses transformasi data ke dalam format tertentu sehingga nantinya data dapat digunakan dan ditelusuri.
- Data Mining
Dalam tahapan ini, akan terjadi proses pencarian pola dengan metode, teknik, dan algoritma tertentu yang bervariasi dan rumit. Pola dan data yang dicari adalah pola dan data yang menarik.
- Interpretasi dan Evaluasi
Setelah menemukan pola dan data menarik, selanjutnya adalah menampilkan data tersebut ke dalam bentuk yang mudah dipahami oleh pengguna atau pihak yang berkepentingan. Jadi pola yang ditemukan nanti akan diperiksa dan dicek apakah bertentangan dengan hipotesis sebelumnya ataukah tidak. Intinya data sudah bisa dibaca dan tentunya akan bermanfaat bagi pihak yang berkepentingan.
Proses Data Mining
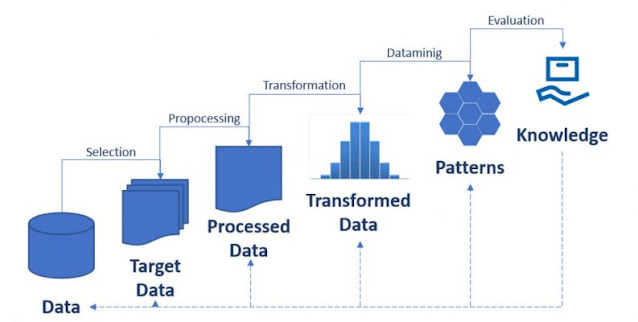
Fase-fase dimulai dari data mentah dan berakhir dengan pengetahuan atau informasi yang telah diolah, yang didapatkan sebagai hasil dari tahapan-tahapan berikut:
- Data Cleansing, juga dikenal sebagai data cleansing, ini adalah sebuah fase dimana data-data tidak lengkap, mengndung error dan tidk konsisten dibuang dari koleksi data, sehingga data yang telah bersih relevan dapat digunakan untuk diproses ulang untuk penggalian pengetahuan(discovery knowledge)
- Data Integration, pada tahap ini terjadi integrasi data,dimana sumber-sumber data yang berulang(multiple data), file-file yang berulang(multiple file), dapat dikombinasikan dan digabungkan kedalam suatu sumber.
- Selection, pada langkah ini, data yang relevan terhadap analisis dapat dipilih dan diterima dari koleksi data yang ada.
- Data Transformation, juga dikenal sebagai data consolidation. Pada tahap ini, dimana data-data yang telah terpilih, ditransformasikan kedalam bentuk-bentuk yang cocok untuk prosedur penggalian (meaning proedure) dengan cara melakukan normalisasi dan agregasi data.
- Data Mining, tahap ini adalah tahap yang paling penting, dengan menggunakan teknik-teknik yang diaplikasikan untuk mengekstrak pola-pola potensial yang berguna.
- Pattern Evaluation, pada tahap ini, pola-pola menarik dengan jelas mempresentasikan pengetahuan telah diidentifikasi berdasarkan measure yang telah diberikan.
- Knowledge Representation, ini merupakan tahap terakhir dimana pengetahuan yang telah ditemukan secara visual ditampilkan kepada user.Tahap penting ini menggunakan teknik visualisasi untuk membantu user dalam mengerti dan menginterpresentasikan hasil dari data mining.
Arsitektur Data Mining
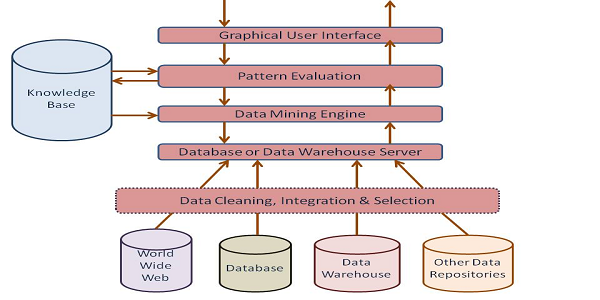
Arsitektur utama dari sistem data mining , pada umumnya terdiri dari beberapa komponen sebagai berikut:
- Basis data (Database), data warehouse , atau media penyimpanan informasi, terdiri dari satu atau beberapa database , data warehouse , atau data dalam bentuk lain. Pembersihan data dan integrasi data dilakukan terhadap data tersebut. Database, data warehose , bertanggung jawab terhadap pencarian data yang relevan sesuai dengan yang diinginkan pengguna atau user .
- Basis pengetahuan (Knowledge Base), merupakan basis pengetahuan yang digunakan sebagai panduan dalam pencarian pola.
- Data mining engine, merupakan bagaian penting dari sistem dan idealnya terdiri dari kumpulan modul-modul fungsi yang digunakan dalam proses karakteristik ( characterization ), klasifikasi ( clasiffication ), dan analisis kluster ( cluster analysis ). Dan merupakan bagian dari software yang menjalankan program berdasarkan algoritma yang ada.
- Evaluasi pola (pattern evaluation), komponen ini pada umumnya berinteraksi dengan modul-modul data mining . Dan bagian dari software yang berfungsi untuk menemukan pattern atau pola-pola yang terdapat dalam database yang diolah sehingga nantinya proses data mining dapat menemukan knowledge yang sesuai.
- Antar muka (Graphical user interface), merupakan modul komunikasi antara pengguna atau user dengan sistem yang memungkinkan pengguna berinteraksi dengan sistem untuk menentukan proses data mining itu sendiri.
Teknik Data Mining
Sebelum mengetahui teknik-teknik yang dapat digunakan dalam data mining terdapat empat operasi yang dapat dihubungkan dengan data mining sebagai berikut.
a). Predictive modeling, ada dua teknik yang dapat dilakukan dalam predictive modeling, yaitu:
- Classification Digunakan untuk membuat dugaan awal tentang class yang spesifik untuk setiap record dalam database dari satu setnilai class yang mungkin
- Value Prediction Digunakan untuk memperkirakan nilai numeric yang kontinu yang trasosiasi dengan record database. Teknik ini menggunakan teknik statistic klasik dari linier regression dan nonlinier regression.
b). Database segmentation Tujuan dabase segmentation adalah untuk mempartisi database menjadi sejumlah segmen, cluster, atau record yang sama, dimana record tersebut diharapkan homogen.
c). Link analysis Tujuan link analysis adalah untuk membuat hubungan antara record yang individual atau sekumpulan record dalam database. Aplikasi pada link analysis meliputi product affinity analysis, direct marketing, dan stock price movement.
d). Deviation detection Teknik ini sering kali merupakan sumber dari penemuan yang benar karena teknik ini mengidentifikasi outlier yang mengekspresikan deviasi dari ekspektasi yang telah diketahui sebelumnya.
e). Nearest Neighbour prediksi pengelompokan dan nearest neighbour merupakan teknik yang tertua yang digunakan dalam data mining. Nearest neighbour merupakan teknik prediksi yang hampir sama dengan pengelompokan, untuk memperkirakan apakah nilai prediksi ada dalam satu record, mencari kesamaan nilai prediktor didalam basis data historis dan menggunakan nilai prediksi dari record yang “Terdekat” untuk tidak membagi-bagikan record.
f). Pengelompokan (Clustering) merupakan metode yang mengklasifikasikan data kedalam kelompok-kelompok berdasarkan kriteria masing-masing data. Biasanya, teknik ini dipakai untuk memberikan pengguna akhir sebuah gambaran level atas dari apa yang telah terjadi didalam basis data. Pengelompokan terkadang digunakan untuk segmentasi.
Teknik generasi selanjutnya (The Next Generation Technique)
g). Decision Tree (Pohon Keputusan) Pohon keputusan merupakan model prediktif yang dapat digambarkan seperti pohon, dimana setiap node didalam struktur pohon tersebut mewakili sebuah pertanyaan yang digunakan untuk menggolongkan data.
Struktur ini dapat digunakan untuk membantu memperkirakan kemungkinan nilai setiap atribut data.
Beberapa hal menarik tentang tree:
- Tree ini membagi data pada setiap cabangnya tanpa kehilangan data sedikit pun. Jumlah total record pada node parent sama dengan jumlah total record yang ada node children.
- Sangat mudah dimengerti bagaimana sebuah model dibangun, kebalikan dengan model dari neural network atau dari statistik standar.
- Mudah untuk menggunakan model ini jika kita mempunyai target pelanggan yang sepertinya tertarik dengan penawaran marketing.
Dari perspektif bisnis, decision tree dapat dilihat sebagai pembuatan segmentasi dari data set yang orisinil. Segmentasi ini dilakukan untuk beberapa alasan tertentu, misalnya untuk prediksi dari beberapa potong informasi penting.
Meskipun decision tree sendiri dan algoritma yang membuat decision tree itu mungkin saja sangat kompleks, namun hasil yang ditampilkan dengan cara yang mudah dimengerti sangat membantu untuk pengguna bisnis.
Decision tree sering kali dikembangkan untuk statistican dalam mengotomatisasi proses menentukan field mana dari database mereka yang benar-benar berguna untuk terkorelasi dengan masalh tertentu yang sedang mereka usahakan untuk mengerti.
Karena itu, algoritma decision tree cenderung mengotomatisasi seluruh proses pembuatan hipotesis dan kemudian melakukan validasi yang lebih komplit dalam cara yang lebih terintegrasi dibanding dengan teknik data mining lainnya.
Decision tree biasanya digunakan untuk berbagai kebutuhan:
- Eksplorasi Teknologi decision tree dapat digunakan untuk eksplorasi data set dan masalah bisnis. Hal ini biasanya dilakukan dengan mencari predictor dan nilai yang dipilih untuk setiap bagian/cabang dari tree tersebut.
- Preprocessing data Teknologi ini juga dapat digunakan untuk mengolah daan memproses data yang dapat digunakan pada algoritma lain, misalnya neural network, nearest neighbour, dan lain-lain.Hal itu karena algoritma lain memerlukan waktu yang relatif lama untuk dijalankan jika terdapat jumlah predictor dalam jumlah besar untuk digunakan sebagai model sehingga teknik decision tree biasanya digunakan pada tahap pertama data mining untuk menciptakan subset yang berguna dari predictor baru kemudian hasil tersebut akan dapat dimasukkan pada teknik data miing yang lain.
- Prediksi Para analis menggunakan teknik ini untuk membangun sebuah model prediktif yang efektif.
Kelebihan Data Mining
Data mining merupakan sebuah proses interatif dan interaktif untuk mendapatkan sebuah pola baru yang menarik. Pola tersebut tentunya akan sangat bermanfaat. Model yang dihasilkan dari proses data mining biasanya sudah sempurna sehingga dapat digeneralisasi untuk kepentingan di masa depan.
Karena prosesnya yang cukup panjang dan rumit, maka dari proses awal biasanya akan menghasilkan sesuatu yang baru, yang tidak diketahui sebelumnya. Sesuatu yang baru ini akan menambah pengetahuan para pengguna ataupun peneliti dan tentunya akan sangat bermanfaat karena dapat digunakan untuk melakukan tindakan tertentu.
Penggalian data juga sering dikatakan sebagai proses interaktif dan interatif. Proses interaktif maksudnya yaitu proses yang masih memerlukan interaksi manusia agar bisa terlaksana. Sedangkan proses interatif, maksudnya adalah proses yang tidak hanya dilakukan sekali, perlu proses yang berulang-ulang untuk mendapatkan data penting yang dimaksud.
Kelebihannya membuat analisa suatu data besar menjadi semakin mudah. Pencarian pola baru atau trend baru bisa dilakukan dengan mudah sehingga bisa membantu mengambil keputusan di masa yang akan datang atau bisa memprediksi data tertentu sehingga bisa menganalisis apa yang harus dilakukan.
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor antara lain:
- Pertumbuhan yang cepat dalam kumpulan data.
- Penyimpanan data dalam data warehouse , sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
- Adanya peningkataan akses data melalui navigasi web dan internet.
- Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
- Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi.
- Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan. (Larose, 2005)
Software Aplikasi Data Mining
Selain alat-alat data mining yang telah disebutkan diatas, Wikipedia memberikan daftar software dan aplikasi bersifat free dan open source yang dapat digunakan untuk data mining antara lain sebagai berikut :
- Carrot2: frameworkclusteringteks dan hasil pencarian.
- org: minerstruktur kimiadanweb search engine.
- ELKI: projectriset universitas dengan analisiscluster canggih danmetode deteksioutlier yangditulis dalam bahasa Java.
- GATE: pemroses bahasa natural dan tool rekayasa bahasa.
- JHepWork: framework analisis data berbasis Java yang dikembangkan di Argonne National Laboratory.
- KNIME: Konstanz Information Miner, framework analisis data komprehensif yang user-friendly.
- ML-Flex: paket software yang memungkinkan pengguna untuk mengintegrasikan dengan paket mesin belajar pihak ketiga yang ditulis dalam bahasa pemrograman apapun, mengeksekusi klasifikasi analisis secara paralel sepanjang node komputasi, dan menghasilkan laporanHTML dari hasil klasifikasi.
- NLTK (Natural Language Toolkit): Sebuah kumpulan libraries dan program untuk pengolahan bahasa simbolik dan statistik alami untuk bahasa Python.
- Orange: Sebuah komponen berbasis data miningdan suitesoftware mesin pembelajaran ditulis dalam bahasaPython.
- R: Sebuah bahasa pemrograman dan lingkungan perangkat lunak untuk komputasi statistik, data mining, dangrafis. Ini adalah bagian dariproyek GNU.
- RapidMiner: Sebuah lingkungan untuk pembelajaran mesin dan eksperimen data mining.
- UIMA: framework komponen untuk menganalisis konten tidak terstruktur seperti teks, audio dan video-awalnya dikembangkan oleh IBM.
- Weka: suitesoftware aplikasi pembelajaran mesin yang ditulis dalam bahasa pemrograman Java.
Sedangkan software dan aplikasi yang bersifat komersial antara lain sebagai berikut :
- Angoss KnowledgeSTUDIO: tool data miningyang dibuat Angoss.
- BIRT Analytics: tool visual data mining dan analisis prediktifyang dibuat Actuate Corporation.
- Clarabridge: solusi analisis text kelas enterprise.
- E-NI (e-mining, e-monitor): tool data mining berbasiskan pola sementara.
- IBM SPSS Modeler: software data mining yang dibuatIBM.
- KXEN Modeler: tool data miningyang dibuat KXEN.
- LIONsolver: software aplikasi terintegrasi untuk data mining, intelegen bisnis, dan pemodelan yang mengimplementasikan pendekatan Learning and Intelligent OptimizatioN (LION).
- Microsoft Analysis Services: software data mining yang dibuatMicrosoft.
- Oracle Data Mining: software data miningoleh Oracle.
- SAS Enterprise Miner: software data mining yang dibuat SAS Institute.
- STATISTICA Data Miner: software data mining yang dibuat StatSoft.
Contoh Penerapan Data Mining
- Analisa pasar dan manajemen. Solusi yang dapat diselesaikan dengan data mining, diantaranya: Menembak target pasar, Melihat pola beli pemakai dari waktu ke waktu, Cross-Market analysis, Profil Customer, Identifikasi kebutuhan Customer, Menilai loyalitas Customer, Informasi Summary.
- Analisa Perusahaan dan Manajemen resiko. Solusi yang dapat diselesaikan dengan data mining, diantaranya: Perencanaan keuangan dan Evaluasi aset, Perencanaan sumber daya (Resource Planning), Persaingan (Competition).
- Sebuah perusahaan telekomunikasi menerapkan data mining untuk melihat dari jutaan transaksi yang masuk, transaksi mana sajakah yang masih harus ditangani secara manual.
- Financial Crimes Enforcement Network di Amerika Serikat baru-baru ini menggunakan data mining untuk me-nambang trilyunan dari berbagai subyek seperti property, rekening bank dan transaksi keuangan lainnya untuk mendeteksi transaksi-transaksi keuangan yang mencurigakan (seperti money laundry) .
- Australian Health Insurance Commision menggunakan data mining untuk mengidentifikasi layanan kesehatan yang sebenarnya tidak perlu tetapi tetap dilakukan oleh peserta asuransi.
- IBM Advanced Scout menggunakan data mining untuk menganalisis statistik permainan NBA (jumlah shots blocked, assists dan fouls) dalam rangka mencapai keunggulan bersaing (competitive advantage) untuk tim New York Knicks dan Miami Heat.
- Jet Propulsion Laboratory (JPL) di Pasadena, California dan Palomar Observatory berhasil menemukan 22 quasar dengan bantuan data mining. Hal ini merupakan salah satu kesuksesan penerapan data mining di bidang astronomi dan ilmu ruang angkasa.
- Internet Web surf-aid IBM Surf-Aid menggunakan algoritma data mining untuk mendata akses halaman Web khususnya yang berkaitan dengan pemasaran guna melihat prilaku dan minat customer serta melihat ke- efektif-an pemasaran melalui Web.
Baca juga : Machine Learning