Teknik Machine Learning
Teknik ini pada umumnya terdiri dari 2 jenis model yaitu Supervised Learning dan Unsupervised Learning.
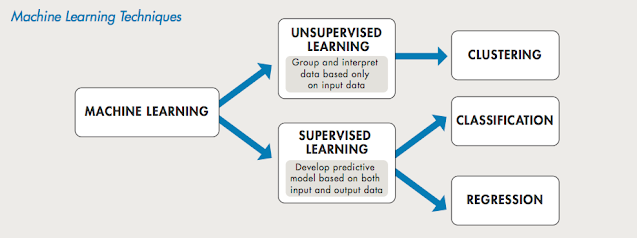
Supervised Learning
Supervised Learning (pembelajaran terarah) adalah salah satu metode pembelajaran mesin dimana hasil yang diharapkan pengguna, sudah diketahui atau dimiliki informasinya oleh sistem. Hal ini berarti bahwa metode pembelajaran ini bekerja dengan memanfaatkan kembali data-data dan hasil output yang pernah dimasukkan oleh pengguna atau dikerjakan oleh sistem sebelumnya. Pada metode ini, pola input dan pola output dibutuhkan untuk mengenali suatu informasi dalam bank memori. Ketika suatu pola input dibentuk, sistem akan meneruskan rangsangan data hingga ke bank memori dan sistem output. Sistem output yang menerima rangsangan data akan menampilkan pola output dan menyocokkan polanya dengan pola input. Jika pola cocok, data akan ditampilkan dari bank memori dalam bentuk output. Apabila pola input dan pola output tidak ada yang cocok, maka outpun akan error. Dan jika nilai error cukup besar, pembelajaran lebih lanjut perlu dilakukan.
Beberapa contoh sistem algoritma yang menerapkan metode Supervised Learning adalah algoritma Hebbian (Hebb Rule), algoritma Perceptron, algoritma Adaline, algoritma Boltzman, algoritma Hapfield, dan algoritma Backpropagation.
Baca juga : Data Mining
Contoh Studi Kasus pemecahan masalah dengan metode Supervised Learning adalah misalnya kita ingin memilah email mana yang termasuk spam dan mana yang bukan. Saat pertama kali kita memutuskan suatu email dari pengirim tertentu adalah spam, sistem tidak memiliki data pemilahan sehingga semua email diterima sebagaimana mestinya. Namun setelah kita menandai email dari suatu pengirim adalah spam, sistem akan secara otomatis terus memasukkan email tersebut ke folder spam sampai kita membatalkan stempel atau pilihan spam pada si pengirim email tersebut.

Unsupervised Learning
Unsupervised Learning (pembelajaran tidak terarah) adalah metode lain dalam materi pembelajaran mesin. Konsep yang metode ini gunakan jauh berbeda dengan metode Supervised Learning dimana pada metode ini hasil yang diharapkan tidak dapat diketahui oleh siapapun. Dengan kata lain, hasil yang akan ditampilkan hanya bergantung kepada nilai bobot yang disusun pada awal pembangunan sistem dan tentu masih dalam ruang lingkup tertentu. Tujuan utama dari metode pembelajaran ini adalah agar para penggunanya dapat mengelompokkan objek-objek yang dinilai sejenis dalam ruang atau area tertentu. Metode pembelajaran ini sangat cocok digunakan untuk mencari atau mengklasifikasi suatu pola dari banyak objek sejenis yang tidak sepenuhnya sama.
Beberapa contoh sistem algoritma yang menggunakan metode Unsupervised Learning adalah algoritma kompetitif, alogritma Hebbian, algoritma Kohonen, algoritma Neocognitron.
Contoh Studi Kasus pemecahan masalah dengan metode Unsupervised Learning adalah misal suatu pusat perbelanjaan ingin melakukan bongkar muat terhadap satu truk berisi sepatu campur. Agar dapat dijual sepatu-sepatu tersebut perlu dikelompokkan brand dan ukurannya. Dalam hal ini, pihak pusat perbelanjaan tidak perlu memasukkan datanya terlebih dahulu karena data yang ada dilapangan saat itulah yang langsung diproses untuk mengelompokkan sepatu-sepatu tersebut sesuai brand dan ukurannya.

Ciri dari Teknik Machine Learning

Gambar diatas merupakan ciri-ciri dari teknik machine learning, pada contoh ini ditambahkan jenis dari reinforcement learning
Algoritma Machine Learning

Classification
Algoritma Naive Bayes
Naïve Bayes Classifier merupakan sebuah metoda klasifikasi yang berakar pada teorema Bayes . Metode pengklasifikasian dg menggunakan metode probabilitas dan statistik yg dikemukakan oleh ilmuwan Inggris Thomas Bayes , yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai Teorema Bayes . Ciri utama dr Naïve Bayes Classifier ini adalah asumsi yg sangat kuat (naïf) akan independensi dari masing-masing kondisi / kejadian.
Menurut Olson Delen (2008) menjelaskan Naïve Bayes unt setiap kelas keputusan, menghitung probabilitas dg syarat bahwa kelas keputusan adalah benar, mengingat vektor informasi obyek. Algoritma ini mengasumsikan bahwa atribut obyek adalah independen. Probabilitas yang terlibat dalam memproduksi perkiraan akhir dihitung sebagai jumlah frekuensi dr ” master ” tabel keputusan.
Naive Bayes Classifier bekerja sangat baik dibanding dengan model classifier lainnya. Hal ini dibuktikan oleh Xhemali , Hinde Stone dalam jurnalnya “Naïve Bayes vs. Decision Trees vs. Neural Networks in the Classification of Training Web Pages” mengatakan bahwa “Naïve Bayes Classifier memiliki tingkat akurasi yg lebih baik dibanding model classifier lainnya”.

Keuntungan penggunan adalah bahwa metoda ini hanya membutuhkan jumlah data pelatihan ( training data ) yg kecil unt menentukan estimasi parameter yg diperlukan dalam proses pengklasifikasian. Karena yg diasumsikan sebagai variable independent, maka hanya varians dr suatu variable dalam sebuah kelas yg dibutuhkan unt menentukan klasifikasi, bukan keseluruhan dr matriks kovarians.
Kegunaan Naïve Bayes
- Mengklasifikasikan dokumen teks seperti teks berita ataupun teks akademis
- Sebagai metode machine learning yang menggunakan probabilitas
- Untuk membuat diagnosis medis secara otomatis
- Mendeteksi atau menyaring spam
Kelebihan Naïve Bayes
- Bisa dipakai untuk data kuantitatif maupun kualitatif
- Tidak memerlukan jumlah data yang banyak
- Tidak perlu melakukan data training yang banyak
- Jika ada nilai yang hilang, maka bisa diabaikan dalam perhitungan.
- Perhitungannya cepat dan efisien
- Mudah dipahami
- Mudah dibuat
- Pengklasifikasian dokumen bisa dipersonalisasi, disesuaikan dengan kebutuhan setiap orang
- Jika digunakan dalaam bahasa pemrograman, code-nya sederhana
- Bisa digunakan untuk klasifikasi masalah biner ataupun multiclass
Kekurangan Naïve Bayes
- Apabila probabilitas kondisionalnya bernilai nol, maka probabilitas prediksi juga akan bernilai nol
- Asumsi bahwa masing-masing variabel independen membuat berkurangnya akurasi, karena biasanya ada korelasi antara variabel yang satu dengan variabel yang lain
- Keakuratannya tidak bisa diukur menggunakan satu probabilitas saja. Butuh bukti-bukti lain untuk membuktikannya.
- Untuk membuat keputusan, diperlukan pengetahuan awal atau pengetahuan mengenai masa sebelumnya. Keberhasilannya sangat bergantung pada pengetahuan awal tersebut Banyak celah yang bisa mengurangi efektivitasnya
- Dirancang untuk mendeteksi kata-kata saja, tidak bisa berupa gambar
Baca juga : Definisi Algoritma
Regression
Regresi merupakan suatu alat ukur yang juga digunakan untuk mengukur ada atau tidaknya korelasi antarvariabel. Istilahregresi yang berarti ramalan atau taksiran pertama kali diperkenalkan oleh Sir Francis Galton pada tahun 1877.
Analisis regresi adalah studi tentang masalah hubungan beberapa variabel yang ditampilkan dalam persamaan matematika (Andi, 2009). Analisis regresi lebih akurat dalam melakukan analisis korelasi, peramalan atau perkiraan nilai variabel terikat pada nilai variabel bebas lebih akurat pula karena pada analisis ini kesulitan dalam menunjukkan slop (tingkat perubahan suatu variabel terhadap variabel lain dapat ditentukan).
Analisis regresi terbagi menjadi dua yaitu regresi linier dan Nonlinier. Analisi regresi linear terdiri dari analisis regresi linear sederhana dan analisis regresi linear berganda. Perbedaan antar keduanya terletak pada jumlah variabel independennya. Regresi linear sederhana hanya memiliki satu variabel independen, sedangkan regresi linear berganda mempunyai banyak variabel independen. Analisis regresi Nonlinier adalah regresi eksponensial.
Liniear Regression
Regresi Linear Sederhana adalah Metode Statistik yang berfungsi untuk menguji sejauh mana hubungan sebab akibat antara Variabel Faktor Penyebab (X) terhadap Variabel Akibatnya. Faktor Penyebab pada umumnya dilambangkan dengan X atau disebut juga dengan Predictor sedangkan Variabel Akibat dilambangkan dengan Y atau disebut juga dengan Response. Regresi Linear Sederhana atau sering disingkat dengan SLR (Simple Linear Regression) juga merupakan salah satu Metode Statistik yang dipergunakan dalam produksi untuk melakukan peramalan ataupun prediksi tentang karakteristik kualitas maupun Kuantitas.
Contoh Penggunaan Analisis Regresi Linear Sederhana dalam Produksi antara lain :
- Hubungan antara Lamanya Kerusakan Mesin dengan Kualitas Produk yang dihasilkan
- Hubungan Jumlah Pekerja dengan Output yang diproduksi
- Hubungan antara suhu ruangan dengan Cacat Produksi yang dihasilkan.
Model Persamaan Regresi Linear Sederhana adalah seperti berikut ini :
Y = a + bX
Dimana :
Y = Variabel Response atau Variabel Akibat (Dependent)
X = Variabel Predictor atau Variabel Faktor Penyebab (Independent)
a = konstanta
b = koefisien regresi (kemiringan); besaran Response yang ditimbulkan oleh Predictor.
Nilai-nilai a dan b dapat dihitung dengan menggunakan Rumus dibawah ini :
a = (Σy) (Σx²) – (Σx) (Σxy)
n(Σx²) – (Σx)²
b = n(Σxy) – (Σx) (Σy)
n(Σx²) – (Σx)²
Berikut ini adalah Langkah-langkah dalam melakukan Analisis Regresi Linear Sederhana :
a. Tentukan Tujuan dari melakukan Analisis Regresi Linear Sederhana
b. Identifikasikan Variabel Faktor Penyebab (Predictor) dan Variabel Akibat (Response)
c. Lakukan Pengumpulan Data
d. Hitung X², Y², XY dan total dari masing-masingnya
e. Hitung a dan b berdasarkan rumus diatas.
f. Buatkan Model Persamaan Regresi Linear Sederhana.
g. Lakukan Prediksi atau Peramalan terhadap Variabel Faktor Penyebab atau Variabel Akibat.
Clustering Method
K-means clustering
K-Means Clustering adalah suatu metode penganalisaan data atau metode Data Mining yang melakukan proses pemodelan tanpa supervisi (unsupervised) dan merupakan salah satu metode yang melakukan pengelompokan data dengan sistem partisi.

Terdapat dua jenis data clustering yang sering dipergunakan dalam proses pengelompokan data yaitu Hierarchical dan Non-Hierarchical, dan K-Means merupakan salah satu metode data clustering non-hierarchical atau Partitional Clustering.

Metode K-Means Clustering berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang berbeda dengan data yang ada di dalam kelompok yang lain.

Dengan kata lain, metode K-Means Clustering bertujuan untuk meminimalisasikan objective function yang diset dalam proses clustering dengan cara meminimalkan variasi antar data yang ada di dalam suatu cluster dan memaksimalkan variasi dengan data yang ada di cluster lainnya.

Data clustering menggunakan metode K-Means Clustering ini secara umum dilakukan dengan algoritma dasar sebagai berikut:
- Tentukan jumlah cluster
- Alokasikan data ke dalam cluster secara random
- Hitung centroid/rata-rata dari data yang ada di masing-masing cluster
- Alokasikan masing-masing data ke centroid/rata-rata terdekat
- Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan di atas nilai threshold yang ditentukan

